∴ | Commonware
Disclaimer. All issues described in this post were responsibly disclosed and resolved during ALPHA-stage development or while still in pull requests, prior to any production deployment.
Last year, we (Team Atlanta) built an autonomous cybersecurity reasoning system, ATLANTIS, that won DARPA’s AI Cyber Challenge (AIxCC), a competition evaluating LLM-driven cyber defense on real-world software. During the 48-hour finals, ATLANTIS uncovered four critical 0-days in SQLite and Apache Commons Compress.
That experience led us to found QED, an AI hacker that autonomously finds bugs and writes exploits end-to-end.
Within a month, we had a working prototype and set out to test it on some of the most security-critical codebases in the world. Blockchain infrastructure and DeFi were an obvious target, and Commonware was one of the systems we chose to analyze.
Our prototype quickly surfaced a non-trivial vulnerability in the BLS threshold cryptography used in Commonware, which we immediately reported to the team and which was promptly fixed.
Following this, Commonware began using QED for PR reviews and periodic full-code scans, where QED autonomously performs bug analysis, generates proof-of-concept exploits, and delivers detailed reports.
In this post, we explore the technical details of some of the more interesting vulnerabilities QED identified. In summary, QED was able to:
- Identify complex vulnerabilities at a level comparable to top-tier human security researchers.
- Autonomously overcome engineering challenges during end-to-end exploit synthesis.
- Perform downstream impact analysis beyond the Commonware codebase.
1. BLS Malleability in C-Simplex
The Bug.
QED identified a bug in the BLS threshold cryptography used in Commonware’s consensus, allowing malicious validators to manipulate leader election or panic other validators. The root cause was treating aggregate BLS verification as proof that each individual component was valid.
Each BLS threshold VRF certificate contains two components:
- The vote signature
V, which signs the consensus payload and round. - The seed signature
S, which signs the round/view identifier and is used as the VRF seed for leader election.
To optimize verification, the protocol checked the aggregate signature V + S in a single BLS aggregate-verification call: aggregate_verify(sig = V + S, messages = [M_vote, M_seed]).
The flaw is that this binds only the sum of the signatures, not the individual components. An attacker who observes a valid pair (V, S) can choose a non-zero group element Δ and construct (V', S') = (V - Δ, S + Δ), which still passes because V' + S' = V + S.
The Discovery.
QED found two concrete attacks by asking what happened after aggregate verification succeeded: where were the individual signature components used? The answer led to two different protocol-level impacts.
Controlling Leader Election
In the threshold-certificate path, the seed signature S was not just certificate metadata. It was extracted after verification and used as leader-election entropy.
Since the aggregate check does not bind S individually, an attacker can grind over Δ values until the rewritten certificate selects a preferred validator, without invalidating the certificate. In effect, the attacker can control the leader outcome induced by that certificate.
Poisoning Threshold Recovery
QED then checked the same aggregation pattern in the pre-certificate path. Partial votes were batch-verified by aggregating partial public keys and partial signatures, inserted into the verified vote set, and later passed into deterministic threshold recovery.
Two Byzantine validators can exploit this by submitting offsetting partial signatures (sig_a', sig_b') = (sig_a + Δ, sig_b - Δ). Once accepted as verified votes, these poisoned partials can make deterministic threshold recovery fail, preventing threshold certificates from forming and stalling consensus.
The Exploit.
QED was able to deterministically demonstrate the vulnerability, thanks to Commonware’s deterministic runtime. Based on our prior experience with writing consensus exploits, AI agents prompted with writing end-to-end exploits against local validator swarms often failed due to non-determinism, falling back to partial demonstrations via unit tests. However, for Commonware, this wasn’t the case. Through the deterministic runtime, QED could precisely introspect network traffic, observe the exact moment an honest node receives a payload (vote/certificate), and replay the same execution while substituting a malicious payload. This enabled a clean, deterministic, end-to-end demonstration of the vulnerability.
The Fix.
Both issues were fixed using random linear combinations. Instead of checking a plain sum, the verifier now mixes each component with a random weight before aggregation. This retains batching while preventing offsetting Δ shifts from passing verification, although at some computational overhead compared to the previous approach.
2. Panic in Reed-Solomon Coding
The Bug.
QED also found a bug in the Reed-Solomon erasure coding implementation that lets a malicious leader panic other peers by sending malformed shards. The bug stems from an inconsistency between encoding and decoding: decode() accepts any padding as long as the Merkle root checks out, while re-encoding always uses canonical zero padding, which produces a different commitment root for the same logical block.
The Discovery.
QED found this bug by reasoning backwards through the block lifecycle.
First, it identified the crash site. When a trusted block is reproposed, shards() re-encodes the block and asserts that the resulting commitment matches the stored one. If not, the node panics:
// consensus/src/marshal/coding/types.rs:329-343pub fn shards(&mut self, strategy: &impl Strategy) -> &[C::StrongShard] { match self.shards { None => { let (commitment, shards) = Self::encode(&self.inner, self.config, strategy); assert_eq!(commitment, self.commitment, "coded block constructed with trusted commitment \ does not match commitment"); // PANIC: non-canonical padding produces a different root } }}Next, it checked whether the commitment could ever differ. Re-encoding always uses canonical zero padding via prepare_data, but the original shards may have had non-zero bytes in the padding region — producing a different Merkle root:
// coding/src/reed_solomon.rs:136-158fn prepare_data(data: Vec<u8>, k: usize, m: usize) -> Vec<Vec<u8>> { // ... let mut padded = vec![0u8; k * shard_len]; // canonical zero padding padded[..u32::SIZE].copy_from_slice(&length_bytes); padded[u32::SIZE..u32::SIZE + data_len].copy_from_slice(&data); // ...}Finally, QED identified why non-canonical shards pass verification at all. During decoding, the Merkle root is rebuilt from the reconstructed shards (preserving non-canonical padding), so the root check passes; and extract_data only reads the declared data length, ignoring the padding entirely:
// coding/src/reed_solomon.rs:161-176fn extract_data(shards: Vec<&[u8]>, k: usize) -> Vec<u8> { // reads 4-byte length prefix, then only data_len bytes data.take(data_len).copied().collect() // ignores padding}
// coding/src/reed_solomon.rs:357-376// re-encodes from attacker's shards, root matches attacker's commitmentif tree.root() != *root { return Err(Error::Inconsistent); }One key takeaway is that explicit assertions and unreachable panics are highly effective at guiding the LLM to search for ways to trigger them.
The Exploit.
For this bug, QED wrote a unit test that directly exercised the ReedSolomonEncoder, which was sufficient to demonstrate the vulnerability. The test constructed shards with non-zero padding, built a Merkle root from them, and fed them into a decoder representing honest peers. The decoder returning Ok(..) indicated that these non-canonical shards were accepted. The test then re-encoded the data and confirmed that encode(decode(encode(..))) produced a different commitment than encode(..), which in production would manifest as an assertion.
The Fix.
This was fixed by hardening extract_data to reject shards with non-canonical padding.
3. Next Pointer Corruption In QMDB
The Bug.
QED also found a complex database corruption scenario in QMDB. This issue arises when a key is deleted within a recursive speculative batch. As a result of applying and committing this batch, QMDB can end up in an inconsistent state.
To understand why this happens, we need a bit more context.:
- QMDB is a key-value store backed by an append-only log with MMR authentication. It maintains a journal of updates and an MMR root; the index of the latest update for a key is its location.
- To keep the in-memory index small, keys are translated into fixed-size representations. Multiple keys may map to the same translated key, which we refer to as collision siblings.
- The Any variant performs updates with speculative batches, which are later merkelized into journal entries. These batches can be recursive, meaning child batches build on the side effects of parent batches.
- The Ordered variant maintains a lexicographical ring over all active keys, enabling efficient exclusion proofs. Each operation log includes a
next_keyfield pointing to the next key in order.
Here’s where things go wrong:
-
Initial State. The database has 3 keys,
A,B, andC, whereBandCare collision siblings andAis in a separate bucket. For example, with theTwoCaptranslator (which uses each key’s 2-byte prefix as the translated key), the keysA = 0x1122...,B = 0xAABB11...,C = 0xAABB22...produce exactly this layout.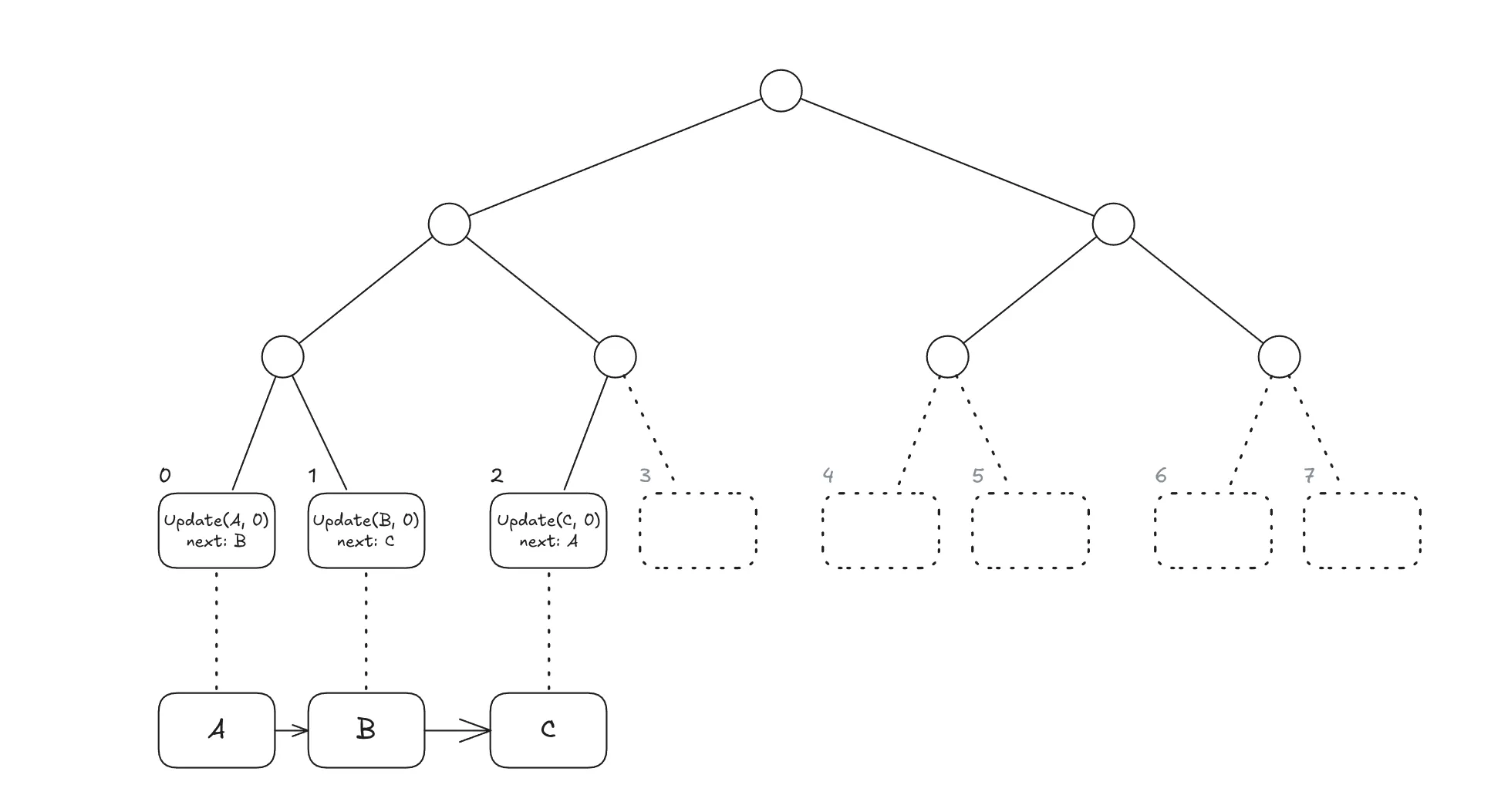
-
Speculative Batch. We create a recursive batch where the parent performs
s[C] = 4and the child performsdelete s[C]. -
Expected Outcome. The merkelization of this recursive batch should result in the following database state. Notice that key
Bwas updated even though its value remained unchanged because it is the predecessor ofC.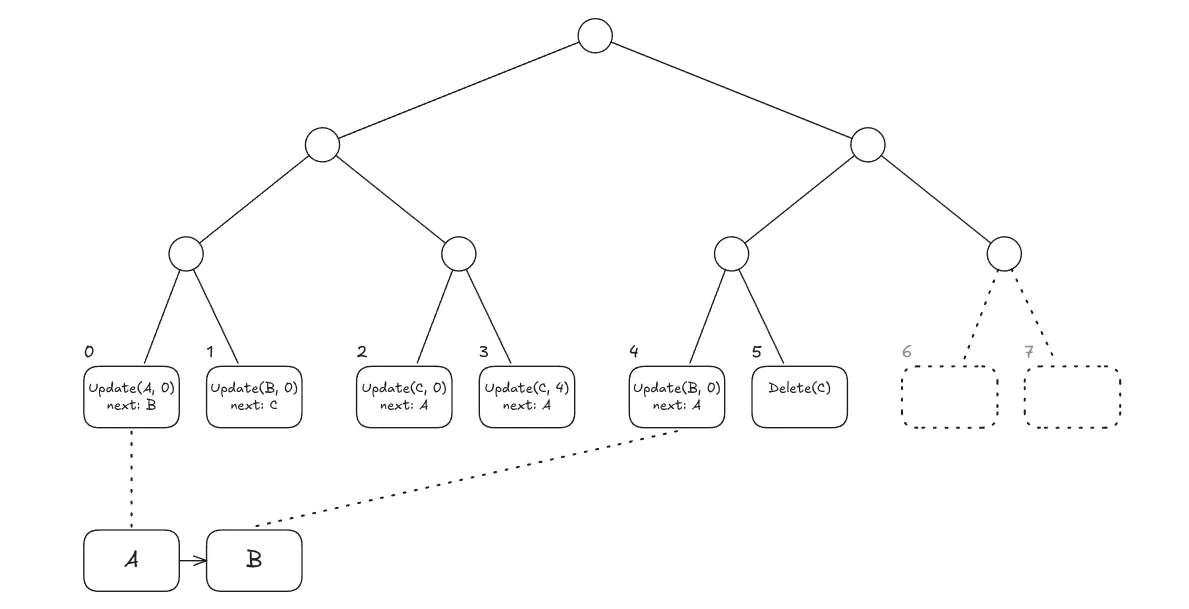
-
Actual Outcome. However, the bug caused the ring to remain at
A → B → C → A, rendering exclusion proofs to yield incorrect results (or hit an assertion).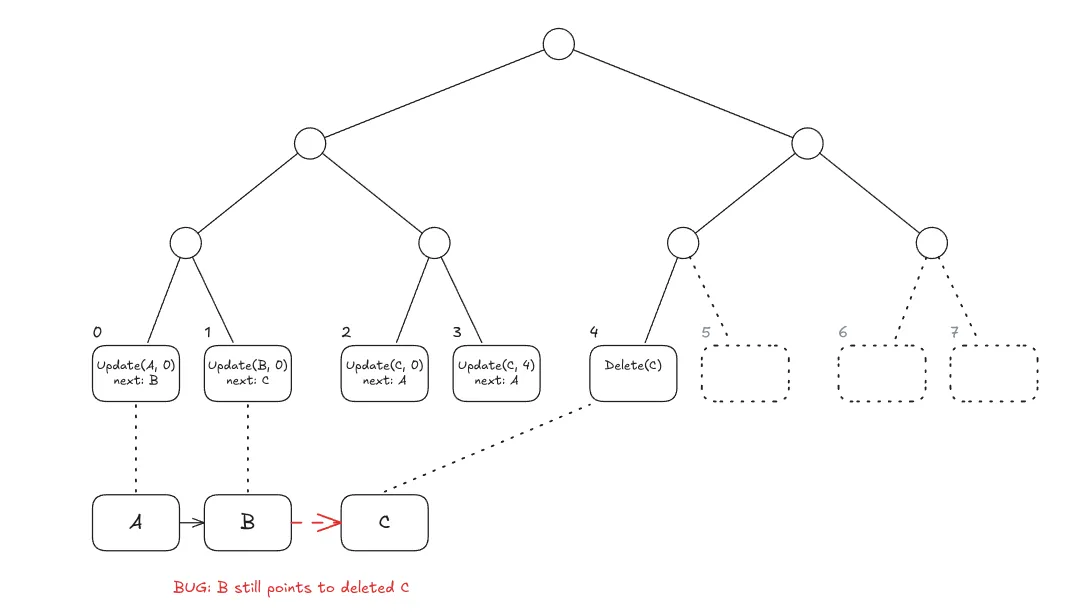
This issue arises from a flaw in QMDB’s predecessor collection logic. The system gathers predecessor candidates from two sources:
- collision siblings via
gather_existing_locations, and - the previous translated bucket.
In this example, gather_existing_locations should return [1, 2], corresponding to the locations of B and C. However, due to a bug in the loop below, it returns only [2].
// [0] mutations = [ Update(C, 4), Delete(C) ], locations = []for key in mutations.keys() { // [1] self.base_diff = { C: Active { V_0 } } if let Some(entry) = self.base_diff.get(key) { if let Some(loc) = entry.loc() { // [2] locations.push(2) locations.push(loc); } continue; // [3] skips db.snapshot.get(key) } locations.extend(db.snapshot.get(key).copied());}// [4] locations = [ 2 ]The problem is that when a key appears in base_diff, the loop unconditionally continues after pushing its location. This prevents the db.snapshot lookup from running, which is necessary to discover other collision siblings in the same bucket. As a result, when C is being deleted, its sibling B is never considered, even though it should be included as a predecessor candidate.
The fix replaces the unconditional continue with an exhaustive match. In the Active case, the code now also performs the db.snapshot lookup, ensuring that all relevant siblings are collected.
The Discovery.
QED found this bug by systematically enumerating the implicit invariants that should be maintained by the code base and partitioning the code base by their themes.
- QED first enumerated 5 implicit invariants that should be maintained by QMDB, one of which was “deterministic roots independent of whether an ancestor is still pending or already committed”.
- QED then sharded the PR’s diff into 17 themed slices and dispatched a swarm of sub-agents to deep-dive each one.
- The slice covering ancestry resolution and freed-ancestor reads in
qmdb/any/batch.rssurfaced a violation for said invariant, titled “a child built on a still-pending parent could leak a stale collision-bucket location throughgather_existing_locationsand produce a different root than the same child built after the parent committed”. - While developing the exploit, QED realized that the differing root was only a tangential symptom, and that the true observable issue was a missed
next_keyupdate. It then refined the PoC to directly capture this behavior.
The Exploit (vs. Fuzzing)
This bug is particularly interesting because it is difficult to manifest as a crash with a coverage-guided fuzzer, as triggering it requires an agentic trial-and-error process to engineer the exploit.
The reason is that QMDB raises the inactivity floor on each speculative batch commit, which suppresses the symptom even without fixing the root cause. In our example, if Update(B, 0) is raised (i.e., rewritten), the merkleizer takes a different path to populate prev_candidates, so the bug no longer manifests.
For a fuzzer to trigger this bug, it would need to insert 20 “buffer” operations before introducing the malicious recursive speculative batch. This is highly unlikely unless the fuzzer is specifically engineered with knowledge of this bug. In contrast, QED produced a working end-to-end PoC by initially failing to trigger the bug, then adapting its strategy by adding the following code block to its PoC.
let mut padding_keys = Vec::new();for i in 0..20u64 { let pk = Digest::from({ let mut p = [0u8; 32]; p[0]=0xCC; p[1]=i as u8; p }); padding_keys.push(pk); commit_writes_generic(&mut db, [(pk, Some(val(100 + i)))], None).await;}The Fix.
This bug was fixed with an exhaustive match on the base_diff entries so that the Active case treats all the collision siblings as a potential predecessor candidate.
4. Downstream Impact Analysis in Stream
The Bug.
In this case, the bug itself was simple, but QED’s downstream analysis made the finding significantly more actionable. QED flagged an issue in the stream module where buffers for DHKE payloads were allocated using config.max_message_size rather than the precise field size, allowing pre-auth actors to allocate large amounts of memory.
The Exploit.
Although the bug was simple, QED did not stop at identifying it and instead empirically validated exploitability. Whether the issue could be exploited depended on several factors:
config.max_message_size: the maximum size of the pre-auth payload, configured by the downstream developermax_concurrent_handshakes: a global rate-limiting counter for concurrent pre-auth connections- network bandwidth: since the rate limiter persists for a fixed duration (e.g., 60s), the attacker must saturate it within that window
Instead of treating this as a generic issue, QED cloned downstream usages (e.g. alto), evaluated default configurations, deployed them via Docker Compose, and measured peak pre-auth memory usage at runtime. Notably, even with max_message_size set to 100 MB, peak pre-auth memory usage is far below 51.2 GB (512 × 100 MB) due to network bandwidth constraints.
| Project | max_message_size | max_concurrent_handshakes | Peak Pre-Auth Memory | Severity |
|---|---|---|---|---|
| Alto | 1 MB | 512 | 512 MB | Low |
| XXX (redacted) | 1 MB | 512 | 512 MB | Low |
| YYY (redacted) | 100 MB | 512 | 10.2 GB | Critical |
The Fix.
QED’s report demonstrated that one of the three downstream implementations was deployed with parameters that made the issue exploitable. Commonware took a preemptive approach to prevent potential downstream disruption by sizing the pre-auth payload to the precise field size rather than config.max_message_size.
Conclusion
QED identified subtle but important issues across core Commonware primitives, including consensus, erasure coding, and storage. These findings were identified during ALPHA-stage development or in-flight pull requests, prior to any production deployment.
QED operated fully autonomously, from bug discovery to PoC generation, functioning as a 24/7 internal code reviewer. We will continue these efforts to maintain a secure foundation so developers building on Commonware can build with confidence. Furthermore, QED will assess Commonware beyond its internal safety, analyzing real-world downstream usage to minimize risk in practice.
We greatly appreciate the Commonware team for maintaining a codebase in a way that is amenable to agentic reasoning. The most impactful factor was the deterministic runtime, which significantly simplified writing end-to-end consensus exploits. Another example is the use of explicit assertions, which provide clear targets for the LLM to trigger and validate.
The vulnerabilities identified by QED are comparable in depth and complexity to those found by experienced human security researchers. They require inferring critical invariants, multi-step data-flow reasoning, and overcoming engineering challenges in writing end-to-end exploits. We were surprised by the extent to which QED could reliably do this.
Despite their apparent complexity, all of these bugs boil down to the same pattern: systems validate a weaker property than what downstream components assume. This is why we believe that, with the right scaffolding to systematize their discovery, many such bug classes can be addressed through agentic security analysis.